Deduplication
Backtrace automatically groups errors and crashes together according to similarity. This grouping allows you to effectively determine which bugs have the highest impact on users, revenue and other important factors. This guide provides a brief overview of the advantages and internals of the deduplication feature.
Depending on your application, crash reports may come in from a few to many thousands a day. Triage and prioritization relies on determining which users are affected by a crash as well as the potential ramifications. Backtrace solves both of these problems through deduplication and classification.
Backtrace automatically groups crashes using a heuristic algorithm (built on a state machine) so that identical crashes are matched together. By default, this grouping allows you to determine the number of impacted hosts or users. With the help of attributes, it is possible to attach other metadata in order to triage by such things as application load, number of impacted versions and more.
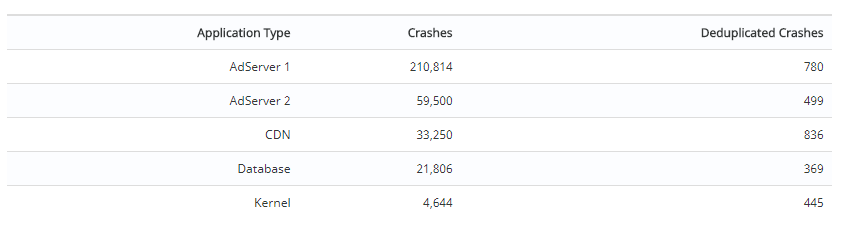
The deduplication mechanism itself greatly reduces the surface area of bugs that engineers have to comb through for purposes of triage. Below are some examples from production workloads ranging from operating system kernels to real-time servers. The crashes column represents the raw number of crashes and the "Deduplicated Crashes" column represents the number of deduplicated crashes with Backtrace.
Deduplication is only one facet of triage. If there is a memory corruption bug or security hole, then a bug may be a ticking time bomb that will eventually manifest as a major denial of service. Backtrace analyzes the memory and executable code of a crash to classify the fault.
Other systems rely on simplistic callstack-based grouping algorithms for determining the uniqueness of a fault. These systems are either too fine-grained or too coarse-grained. If deduplication is too fine-grained, the same bug impacting a large number of users may manifest as many unique bugs impacting a small set of users. If deduplication is too coarse-grained, then the impact of bugs will be inflated leading to incorrect prioritization.
Core to the Backtrace deduplication algorithm is a state machine that is driven by a domain-specific language that allows for transformations of an input callstack for the purposes of both pretty-printing and signature generation. These callstacks are different, one is optimized for human-readability while the other is optimized for grouping purposes. Enterprise customers are able to modify these rule sets for their applications. Otherwise, both cloud and enterprise customers benefit from frequent updates of these rules to better improve out-of-the-box grouping capabilities.
Capabilities
Backtrace uses a dynamic system that intelligently determines which portions of the callstack should be used, ignored and the level of information to be used for any given frame (line numbers, shared library, etc.).
- Library, platform, error handling functions and other boiler-plate are ignored or short-circuit signature generation. This ensures the same bugs are grouped together according to root-cause without being affected by run-time non-determinism unrelated to the crash.
- Compiler-generated names are normalized. This ensures that the same bugs are grouped together across compilation.
- Functions subject to dynamic dispatch on platform features are normalized. This ensures bugs are grouped accurately even in the presence of different processor features.
- Event dispatchers are normalized. This ensures that event-based systems or systems making use of advanced C++ features are grouped accurately according to the deterministic portions of the callstack related to the crash.
- Platform specialization. Backtrace includes advanced rulesets for C++, C, Linux, Windows, Mac OS and popular application frameworks so that only the relevant portions of the callstack are used.
- Object bypass for callback-based systems. Backtrace is able to detect callback-based interfaces and appropriately ignore boiler-plate leading to callback execution.
- The mechanism is extremely configurable and expressive enough that a few simple rules are sufficient for new application frameworks.
Backtrace Versus Conventional Deduplication
Group By First Application Frame
Some systems will group according to the first application frame. This quickly starts to fall apart for many reasons including internal application error handling, faults in external libraries and more. More likely than not, such a system is too coarse-grained to be useful.
Take the following example for a program called program.exe. The callstack of the crashing thread is abort → application_abort → a → b where application_abort is the first application frame. Competing systems will group by application_abort. This function is invoked in almost all cases where the application is explicitly aborted, leading to grossly ineffective deduplication.
This mechanism breaks down for any commonly-used functions, not just error handling functions. For example, let's say a bug was introduced that leads to a fault in a commonly called utility function. These systems would group these faults by the utility function rather than the caller.
Last but not least, these mechanisms disable the ability of doing callstack-analysis for non-deterministic bugs. There may be hundreds of different callstacks for the same bug. Backtrace retains relevant portions of the stack which enables advanced statistical analysis and visualizations on faulting callstacks.
Backtrace intelligently determines which frames to use to avoid situations like this.
Group By Callstack
On the other end of the spectrum is pure callstack-based grouping. This mechanism tends to be too fine-grained, leading to inaccurate aggregation of faults. Modern applications have a high degree of non-determinism both in their surrounding platform libraries as well as application code. In an event-based system, the same function could be invoked by an event loop processor in many different ways. If there is a hang condition, there are many different locations the hang may manifest.
Some systems attempt to improve on this through restrictions such as only considering application frames. This also starts to break down as crucial application libraries end up being completely ignored for the purposes of fault aggregation.
Backtrace intelligently determines which frames to use to avoid situations like this.
Group By Error Type or Exception Message
Some systems will group simply by the type of error condition or an exception message. It goes without saying that this is insufficient for a vast majority of real-world faults. An exception message may be as generic as "failed to complete user action". Since the grouping is too coarse-grained, triage and prioritization is ineffective on these systems.
Signature Lists
Other systems approach this problem by using callstack-based grouping with giant lists of functions to include or exclude for the purposes of deduplication. Unfortunately, these systems are not flexible enough to handle compiler-generated names, non-deterministic callback interfaces and more. Backtrace has flexibility built in that allows a few simple rules that will fit a majority of use-cases without resorting to giant lists that require frequent maintenance.
How Are Rules Improved?
The system has generic rules that have been extrapolated from hundreds of thousands of crashes from complex real-world applications such as highly-multithreaded servers with event dispatch (50000+ threads) and complex desktop applications such as Firefox and Chrome. Whenever a new customer is on-boarded, our engineers will perform anonymized statistical analysis on faults so we constantly improve the core deduplication algorithm and surrounding rulesets.